
In many ways, the introduction of AI has increased our productive capacity when delivering written texts and documents. However, the fundamental requirement of research, which lies at the bottom of every human activity and is the core of any actual expertise, remains unchanged.
The burden of proof when it comes to demonstrating something we believe to be true still follows the regular paths of observation and the scientific method. This is not only because we can, in theory, create AI models with the sole purpose of misguiding the public, but also because the transfer of information is still fundamentally a human endeavor.
A practicality that often gets overlooked when working with AI systems is questioning the limits of their portrayed knowledge. It is interesting that we have grown to assume complete infallibility in the technology, but the models themselves can be very useful in determining the time horizons of their available knowledge.
Let’s assume, for instance, that I’m potentially interested in documenting an opinion that requires knowledge of CO2 emissions in the construction industry. We will produce a rather vague scenario to illustrate our point and focus on the European Union as a territory as opposed to a single country.
A good starting point would be tailoring the prompt in a fashion that makes it possible for me to obtain the desired information while also identifying the possible limits imposed on the tool. Ensuring that we do so in one interaction is also key to saving computational resources and is actually more environmentally friendly.
The prompt, therefore, could be shaped as follows:
“Hi, I’m interested in knowing any relevant regulation in the European Union regarding carbon emissions affecting the construction industry, please. Additionally, I would appreciate it if you could tell me when the training of the current model you’re using to answer was concluded to check if there are any more recent changes or more up-to-date information to be considered.“
As usual, we get different results from different models, though the results are quite similar at first glance:
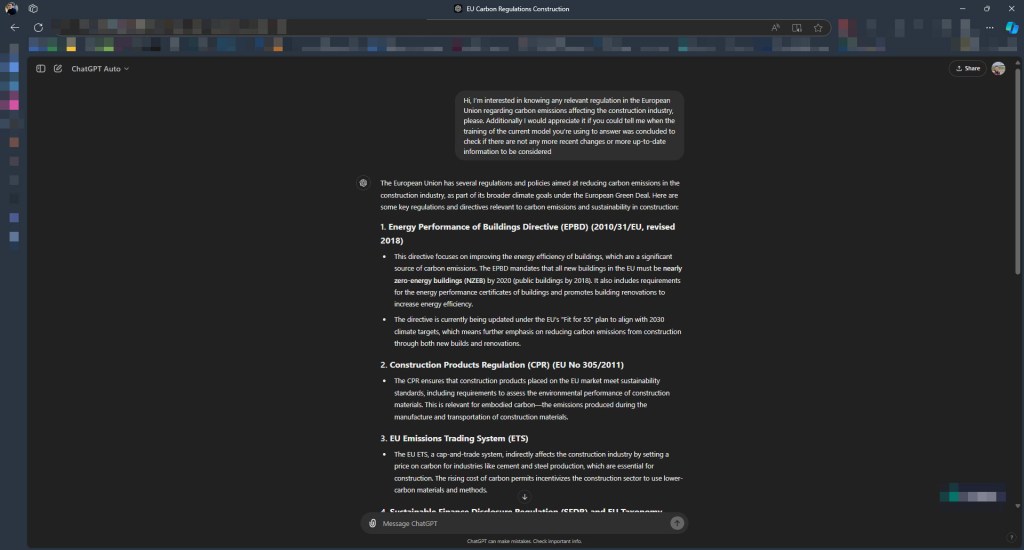
Figure: Information request posted to ChatGPT.
There is, however, a very interesting comment noted at the end of our interactions pertaining to the training period of the model when it comes to this information. ChatGPT, for instance, reports training data dating back to September 2021 (GPT 4.0) and specifies that “any developments, updates, or regulations introduced after that date may not be reflected in the information I provide.“
On a similar note, Claude also provides us with a comparable answer:
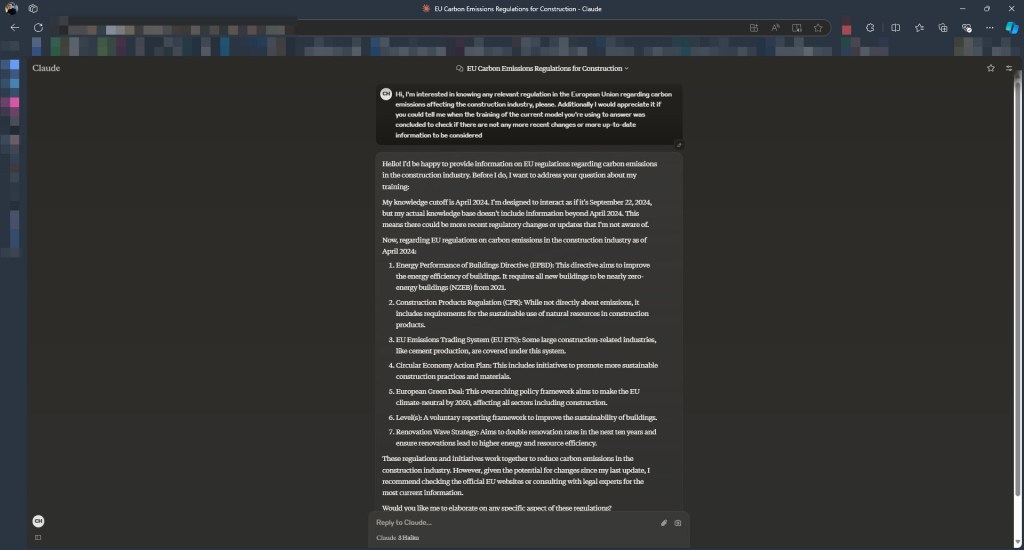
Figure: Information request posted to Claude.
In this case, we are provided the following warning: “My knowledge cutoff is April 2024. I’m designed to interact as if it’s September 22, 2024, but my actual knowledge base doesn’t include information beyond April 2024.”
And lastly, Copilot, which we could argue has access to internet resources, states:
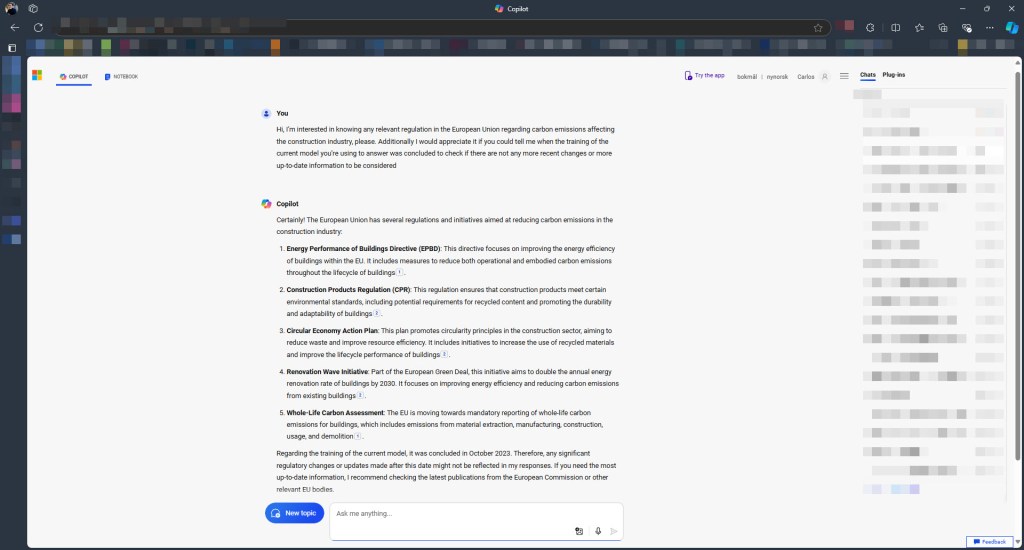
Figure: Information request posted to Copilot
“Regarding the training of the current model, it was concluded in October 2023. Therefore, any significant regulatory changes or updates made after this date might not be reflected in my responses.”
This proves the point. It’s not that AI models are defective or wrong, but rather that they are tools. When dealing with data and information, the value of human expertise can rarely be superseded, at least for now, by even our most advanced models.
Therefore, the ultimate product can be traced once more to the final user, which highlights the most important task of the human operator: controlling the relevance of the provided data and ensuring the general quality of the research that ultimately goes to the public.





Share what you think!